[March 19, 2025] Master the SPLK-1002 Splunk Core Certified Power User Exam With Free Practice Exam
The SPLK-1002 Splunk Core Certified Power User exam is an essential certification for IT professionals who want to validate their skills in using Splunk’s core search and reporting capabilities. This certification proves your ability to create and optimize searches, use knowledge objects, and develop reports and dashboards efficiently within Splunk. If you’re planning to take the SPLK-1002 exam, this guide will help you understand the key topics covered and provide a free practice test to assess your knowledge.
Free SPLK-1002 Practice Exam Questions
1.Which of the following Statements about macros is true? (select all that apply)
A. Arguments are defined at execution time.
B. Arguments are defined when the macro is created.
C. Argument values are used to resolve the search string at execution time.
D. Argument values are used to resolve the search string when the macro is created.
Answer: B, C
Explanation:
A macro is a way to save a commonly used search string as a variable that you can reuse in other searches1. When you create a macro, you can define arguments that are placeholders for values that you specify at execution time1. The argument values are used to resolve the search string when the macro is invoked, not when it is created1. Therefore, statements B and C are true, while statements A and D are false.
2.What is required for a macro to accept three arguments?
A. The macro’s name ends with (3).
B. The macro’s name starts with (3).
C. The macro’s argument count setting is 3 or more.
D. Nothing, all macros can accept any number of arguments.
Answer: A
Explanation:
To create a macro that accepts arguments, you must include the number of arguments in parentheses at the end of the macro name1. For example, my_macro(3) is a macro that accepts three arguments. The number of arguments in the macro name must match the number of arguments in the definition1. Therefore, option A is correct, while options B, C and D are incorrect.
3.Which of the following statements describes POST workflow actions?
A. POST workflow actions are always encrypted.
B. POST workflow actions cannot use field values in their URI.
C. POST workflow actions cannot be created on custom sourcetypes.
D. POST workflow actions can open a web page in either the same window or a new .
Answer: D
Explanation:
A workflow action is a link that appears when you click an event field value in your search results1. A workflow action can open a web page or run another search based on the field value1. There are two types of workflow actions: GET and POST1. A GET workflow action appends the field value to the end of a URI and opens it in a web browser1. A POST workflow action sends the field value as part of an HTTP request to a web server1. You can configure a workflow action to open a web page in either the same window or a new window1. Therefore, option D is correct, while options A, B and C are incorrect.
4.Which of the following searches show a valid use of macro? (Select all that apply)
A. index=main source=mySource oldField=* |’makeMyField(oldField)’| table _time newField
B. index=main source=mySource oldField=* | stats if(‘makeMyField(oldField)’) | table _time newField
C. index=main source=mySource oldField=* | eval newField=’makeMyField(oldField)’| table _time newField
D. index=main source=mySource oldField=* | “‘newField(‘makeMyField(oldField)’)'” | table _time newField
Answer: A, C
Explanation:
Reference: https://answers.splunk.com/answers/574643/field-showing-an-additional-and-not-visible-value-1.html
To use a macro in a search, you must enclose the macro name and any arguments in single quotation marks1. For example, ‘my_macro(arg1, arg2)’ is a valid way to use a macro with two arguments. You can use macros anywhere in your search string where you would normally use a search command or expression1. Therefore, options A and C are valid searches that use macros, while options B and D are invalid because they do not enclose the macros in single quotation marks.
5.Which of the following workflow actions can be executed from search results? (select all that apply)
A. GET
B. POST
C. LOOKUP
D. Search
Answer: A, B, D
Explanation:
As mentioned before, there are two types of workflow actions: GET and POST1. Both types of workflow actions can be executed from search results by clicking on an event field value that has a workflow action configured for it1. Another type of workflow action is Search, which runs another search based on the field value1. Therefore, options A, B and D are correct, while option C is incorrect because LOOKUP is not a type of workflow action.
6.Which of the following is the correct way to use the data model command to search field in the data model within the web dataset?
A. | datamodel web search | filed web *
B. | Search datamodel web web | filed web*
C. | datamodel web web field | search web*
D. Datamodel=web | search web | filed web*
Answer: A
Explanation:
The data model command allows you to run searches on data models that have been accelerated1. The syntax for using the data model command is | datamodel <model_name> <dataset_name> [search <search_string>]1. Therefore, option A is the correct way to use the data model command to search fields in the data model within the web dataset. Options B and C are incorrect because they do not follow the syntax for the data model command. Option D is incorrect because it does not use the data model command at all.
7.Which of the following searches will return events contains a tag name Privileged?
A. Tag= Priv
B. Tag= Pri*
C. Tag= Priv*
D. Tag= Privileged
Answer: B
Explanation:
Reference: https://docs.splunk.com/Documentation/PCI/4.1.0/Install/PrivilegedUserActivity
A tag is a descriptive label that you can apply to one or more fields or field values in your events1. You can use tags to simplify your searches by replacing long or complex field names or values with short and simple tags1. To search for events that contain a tag name, you can use the tag keyword followed by an equal sign and the tag name1. You can also use wildcards (*) to match partial tag names1. Therefore, option B is correct because it will return events that contain a tag name that starts with Pri. Options A and D are incorrect because they will only return events that contain an exact tag name match. Option C is incorrect because it will return events that contain a tag name that starts with Priv, not Privileged.
8.Which of the following statements describes this search?
sourcetype=access_combined I transaction JSESSIONID | timechart avg (duration)
A. This is a valid search and will display a timechart of the average duration, of each transaction event.
B. This is a valid search and will display a stats table showing the maximum pause among transactions.
C. No results will be returned because the transaction command must include the startswith and endswith options.
D. No results will be returned because the transaction command must be the last command used in the search pipeline.
Answer: A
Explanation:
This search uses the transaction command to group events that share a common value for JSESSIONID into transactions1. The transaction command assigns a duration field to each transaction, which is the difference between the latest and earliest timestamps of the events in the transaction1. The search then uses the timechart command to create a time-series chart of the average duration of each transaction1. Therefore, option A is correct because it describes the search accurately. Option B is incorrect because the search does not use the stats command or the pause field. Option C is incorrect because the transaction command does not require the startswith and endswith options, although they can be used to specify how to identify the beginning and end of a transaction1. Option D is incorrect because the transaction command does not have to be the last command in the search pipeline, although it is often used near the end of a search1.
9.Calculated fields can be based on which of the following?
A. Tags
B. Extracted fields
C. Output fields for a lookup
D. Fields generated from a search string
Answer: B
Explanation:
Reference: https://docs.splunk.com/Documentation/Splunk/8.0.3/Knowledge/definecalcfields
A calculated field is a field that you create based on the value of another field or fields1. You can use calculated fields to enrich your data with additional information or to transform your data into a more useful format1. Calculated fields can be based on extracted fields, which are fields that are extracted from your raw data using various methods such as regular expressions, delimiters, or key-value pairs1. Therefore, option B is correct, while options A, C and D are incorrect because tags, output fields for a lookup, and fields generated from a search string are not types of extracted fields.
10.Based on the macro definition shown below, what is the correct way to execute the macro in a search string?
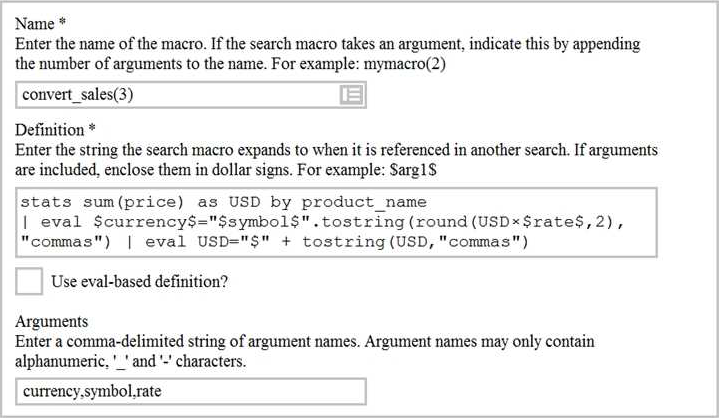
A. Convert_sales (euro, €, 79)”
B. Convert_sales (euro, €, .79)
C. Convert_sales ($euro, $€$, s79$
D. Convert_sales ($euro, $€$, S,79$)
Answer: B
Explanation:
Reference: https://docs.splunk.com/Documentation/Splunk/8.0.3/Knowledge/Usesearchmacros
The correct way to execute the macro in a search string is to use the format macro_name($arg1$,
$arg2$, …) where $arg1$, $arg2$, etc. are the arguments for the macro. In this case, the macro name is convert_sales and it takes three arguments: currency, symbol, and rate. The arguments are enclosed in dollar signs and separated by commas. Therefore, the correct way to execute the macro is convert_sales($euro$, $€$, .79).
11.When multiple event types with different color values are assigned to the same event, what determines the color displayed for the events?
A. Rank
B. Weight
C. Priority
D. Precedence
Answer: C
Explanation:
Reference: https://docs.splunk.com/Documentation/SplunkCloud/8.0.2003/Knowledge/Defineeventtypes When multiple event types with different color values are assigned to the same event, the color displayed for the events is determined by the priority of the event types. The priority is a numerical value that indicates how important an event type is. The higher the priority, the more important the event type. The event type with the highest priority will determine the color of the event.
12.Which of the following statements describes the command below (select all that apply)
Sourcetype=access_combined | transaction JSESSIONID
A. An additional filed named maxspan is created.
B. An additional field named duration is created.
C. An additional field named eventcount is created.
D. Events with the same JSESSIONID will be grouped together into a single event.
Answer: B, C, D
Explanation:
The command sourcetype=access_combined | transaction JSESSIONID does three things:
It filters the events by the sourcetype access_combined, which is a predefined sourcetype for Apache web server logs.
It groups the events by the field JSESSIONID, which is a unique identifier for each user session.
It creates a single event from each group of events that share the same JSESSIONID value. This single event will have some additional fields created by the transaction command, such as duration, event count, and startime.
Therefore, the statements B, C, and D are true.
13.Which of the following can be used with the eval command tostring function (select all that apply)
A. ‘’hex’’
B. ‘’commas’’
C. ‘’Decimal’’
D. ‘’duration’’
Answer: A, B, D
Explanation:
https://docs.splunk.com/Documentation/Splunk/8.1.0/SearchReference/ConversionFunctions#tostri ng.28X.2CY.29
The tostring function in the eval command converts a numeric value to a string value. It can take an optional second argument that specifies the format of the string value. Some of the possible formats are:
hex: converts the numeric value to a hexadecimal string.
commas: adds commas to separate thousands in the numeric value.
duration: converts the numeric value to a human-readable duration string, such as “2h 3m 4s”.
Therefore, the formats A, B, and D can be used with the tostring function.
14.Which of the following statements about tags is true?
A. Tags are case insensitive.
B. Tags are created at index time.
C. Tags can make your data more understandable.
D. Tags are searched by using the syntax tag:: <fieldneme>
Answer: C
Explanation:
Tags are aliases or alternative names for field values in Splunk. They can make your data more understandable by using common or descriptive terms instead of cryptic or technical terms. For example, you can tag a field value such as “200” with “OK” or “success” to indicate that it is a HTTP status code for a successful request. Tags are case sensitive, meaning that “OK” and “ok” are different tags. Tags are created at search time, meaning that they are applied when you run a search on your data. Tags are searched by using the syntax tag::<tagname>, where <tagname> is the name of the tag you want to search for.
15.Which of the following statements about data models and pivot are true? (select all that apply)
A. They are both knowledge objects.
B. Data models are created out of datasets called pivots.
C. Pivot requires users to input SPL searches on data models.
D. Pivot allows the creation of data visualizations that present different aspects of a data model.
Answer: D
Explanation:
Data models and pivot are both knowledge objects in Splunk that allow you to analyze and visualize your data in different ways. Data models are collections of datasets that represent your data in a structured and hierarchical way. Data models define how your data is organized into objects and fields. Pivot is a user interface that allows you to create data visualizations that present different aspects of a data model. Pivot does not require users to input SPL searches on data models, but rather lets them select options from menus and forms. Data models are not created out of datasets called pivots, but rather pivots are created from datasets in data models.
16.When using the Field Extractor (FX), which of the following delimiters will work? (select all that apply)
A. Tabs
B. Pipes
C. Colons
D. Spaces
Answer: A, B, D
Explanation:
Reference: https://docs.splunk.com/Documentation/Splunk/8.0.3/Knowledge/FXSelectMethodstep https://community.splunk.com/t5/Splunk-Search/Field-Extraction-Separate-on-Colon/m-p/29751
The Field Extractor (FX) is a tool that helps you extract fields from your data using delimiters or regular expressions. Delimiters are characters or strings that separate fields in your data.
Some of the delimiters that will work with FX are:
Tabs: horizontal spaces that align text in columns.
Pipes: vertical bars that often indicate logical OR operations.
Spaces: blank characters that separate words or symbols.
Therefore, the delimiters A, B, and D will work with FX.
17.Which of the following describes the Splunk Common Information Model (CIM) add-on?
A. The CIM add-on uses machine learning to normalize data.
B. The CIM add-on contains dashboards that show how to map data.
C. The CIM add-on contains data models to help you normalize data.
D. The CIM add-on is automatically installed in a Splunk environment.
Answer: C
Explanation:
The Splunk Common Information Model (CIM) add-on is a Splunk app that contains data models to help you normalize data from different sources and formats. The CIM add-on defines a common and consistent way of naming and categorizing fields and events in Splunk. This makes it easier to correlate and analyze data across different domains, such as network, security, web, etc. The CIM add-on does not use machine learning to normalize data, but rather relies on predefined field names and values. The CIM add-on does not contain dashboards that show how to map data, but rather provides documentation and examples on how to use the data models. The CIM add-on is not automatically installed in a Splunk environment, but rather needs to be downloaded and installed from Splunkbase.
18.What does the transaction command do?
A. Groups a set of transactions based on time.
B. Creates a single event from a group of events.
C. Separates two events based on one or more values.
D. Returns the number of credit card transactions found in the event logs.
Answer: B
Explanation:
The transaction command is a search command that creates a single event from a group of events that share some common characteristics. The transaction command can group events based on fields, time, or both. The transaction command can also create some additional fields for each transaction, such as duration, eventcount, startime, etc. The transaction command does not group a set of transactions based on time, but rather groups a set of events into a transaction based on time. The transaction command does not separate two events based on one or more values, but rather joins multiple events based on one or more values. The transaction command does not return the number of credit card transactions found in the event logs, but rather creates transactions from the events that match the search criteria.
19.Which of the following statements describe data model acceleration? (select all that apply)
A. Root events cannot be accelerated.
B. Accelerated data models cannot be edited.
C. Private data models cannot be accelerated.
D. You must have administrative permissions or the accelerate_dacamodel capability to accelerate a data model.
Answer: B, C, D
Explanation:
Data model acceleration is a feature that speeds up searches on data models by creating and storing summaries of the data model datasets1. To enable data model acceleration, you must have administrative permissions or the accelerate_datamodel capability1. Therefore, option D is correct. Accelerated data models cannot be edited unless you disable the acceleration first1. Therefore, option B is correct. Private data models cannot be accelerated because they are not visible to other users1. Therefore, option C is correct. Root events can be accelerated as long as they are not based on a search string1. Therefore, option A is incorrect.
20.A user wants to convert numeric field values to strings and also to sort on those values.
Which command should be used first, the eval or the sort?
A. It doesn’t matter whether eval or sort is used first.
B. Convert the numeric to a string with eval first, then sort.
C. Use sort first, then convert the numeric to a string with eval.
D. You cannot use the sort command and the eval command on the same field.
Answer: C
Explanation:
The eval command is used to create new fields or modify existing fields based on an expression2. The sort command is used to sort the results by one or more fields in ascending or descending order2. If you want to convert numeric field values to strings and also sort on those values, you should use the sort command first, then use the eval command to convert the values to strings2. This way, the sort command will use the original numeric values for sorting, rather than the converted string values which may not sort correctly. Therefore, option C is correct, while options A, B and D are incorrect.
21.The Field Extractor (FX) is used to extract a custom field. A report can be created using this custom field. The created report can then be shared with other people in the organization.
If another person in the organization runs the shared report and no results are returned, why might this be? (select all that apply)
A. Fast mode is enabled.
B. The dashboard is private.
C. The extraction is private-
D. The person in the organization running the report does not have access to the index.
Answer: C, D
Explanation:
The Field Extractor (FX) is a tool that helps you extract fields from your events using a graphical interface2. You can create a report using a custom field extracted by the FX and share it with other users in your organization2. However, if another user runs the shared report and no results are returned, there could be two possible reasons. One reason is that the extraction is private, which means that only you can see and use the extracted field2. To make the extraction available to other users, you need to make it global or app-level2. Therefore, option C is correct. Another reason is that the other user does not have access to the index where the events are stored2. To fix this issue, you need to grant the appropriate permissions to the other user for the index2. Therefore, option D is correct. Options A and B are incorrect because they are not related to the field extraction or the report.
22.Which of the following data model are included In the Splunk Common Information Model (CIM) add-on? (select all that apply)
A. Alerts
B. Email
C. Database
D. User permissions
Answer: A, B, C
Explanation:
Reference: https://docs.splunk.com/Documentation/CIM/4.15.0/User/Overview
The Splunk Common Information Model (CIM) add-on is a collection of pre-built data models and knowledge objects that help you normalize your data from different sources and make it easier to analyze and report on it3. The CIM add-on includes several data models that cover various domains such as Alerts, Email, Database, Network Traffic, Web and more3. Therefore, options A, B and C are correct because they are names of some of the data models included in the CIM add-on. Option D is incorrect because User permissions is not a name of a data model in the CIM add-on.
23.A field alias has been created based on an original field. A search without any transforming commands is then executed in Smart Mode.
Which field name appears in the results?
A. Both will appear in the All Fields list, but only if the alias is specified in the search.
B. Both will appear in the Interesting Fields list, but only if they appear in at least 20 percent of events.
C. The original field only appears in All Fields list and the alias only appears in the Interesting Fields list.
D. The alias only appears in the All Fields list and the original field only appears in the Interesting Fields list.
Answer: B
Explanation:
A field alias is a way to assign an alternative name to an existing field without changing the original field name or value2. You can use field aliases to make your field names more consistent or descriptive across different sources or sourcetypes2. When you run a search without any transforming commands in Smart Mode, Splunk automatically identifies and displays interesting fields in your results2. Interesting fields are fields that appear in at least 20 percent of events or have high variability among values2. If you have created a field alias based on an original field, both the original field name and the alias name will appear in the Interesting Fields list if they meet these criteria2. However, only one of them will appear in each event depending on which one you have specified in your search string2. Therefore, option B is correct, while options A, C and D are incorrect.
24.When performing a regular expression (regex) field extraction using the Field Extractor (FX), what happens when the require option is used?
A. The regex can no longer be edited.
B. The field being extracted will be required for all future events.
C. The events without the required field will not display in searches.
D. Only events with the required string will be included in the extraction.
Answer: D
Explanation:
The Field Extractor (FX) allows you to use regular expressions (regex) to extract fields from your events using a graphical interface or by manually editing the regex2. When you use the FX to perform a regex field extraction, you can use the require option to specify a string that must be present in an event for it to be included in the extraction2. This way, you can filter out events that do not contain the required string and focus on the events that are relevant for your extraction2. Therefore, option D is correct, while options A, B and C are incorrect.
25.Which group of users would most likely use pivots?
A. Users
B. Architects
C. Administrators
D. Knowledge Managers
Answer: A
Explanation:
Reference: https://docs.splunk.com/Documentation/Splunk/8.0.3/Pivot/IntroductiontoPivot
A pivot is a tool that allows you to create reports and dashboards using data models without writing any SPL commands2. You can use pivots to explore, filter, split and visualize your data using a graphical interface2. Pivots are designed for users who want to analyze and report on their data without having to learn the SPL syntax or the underlying structure of the data2. Therefore, option A is correct, while options B, C and D are incorrect because they are not the typical group of users who would use pivots.
26.When using timechart, how many fields can be listed after a by clause?
A. because timechart doesn’t support using a by clause.
B. because _time is already implied as the x-axis.
C. because one field would represent the x-axis and the other would represent the y-axis.
D. There is no limit specific to timechart.
Answer: B
Explanation:
The timechart command is used to create a time-series chart of statistical values based on your search results2. You can use the timechart command with a by clause to split the results by one or more fields and create multiple series in the chart2. However, you can only list one field after the by clause when using the timechart command because _time is already implied as the x-axis of the chart2. Therefore, option B is correct, while options A, C and D are incorrect.
27.What is the correct syntax to search for a tag associated with a value on a specific fields?
A. Tag-<field?
B. Tag<filed(tagname.)
C. Tag=<filed>::<tagname>
D. Tag::<filed>=<tagname>
Answer: D
Explanation:
Reference: https://docs.splunk.com/Documentation/Splunk/8.0.3/Knowledge/TagandaliasfieldvaluesinSplunkWeb
A tag is a descriptive label that you can apply to one or more fields or field values in your events2. You can use tags to simplify your searches by replacing long or complex field names or values with short and simple tags2. To search for a tag associated with a value on a specific field, you can use the following syntax: tag::<field>=<tagname>2. For example, tag::status=error will search for events where the status field has a tag named error. Therefore, option D is correct, while options A, B and C are incorrect because they do not follow the correct syntax for searching tags.
28.What functionality does the Splunk Common Information Model (CIM) rely on to normalize fields with different names?
A. Macros.
B. Field aliases.
C. The rename command.
D. CIM does not work with different names for the same field.
Answer: B
Explanation:
The Splunk Common Information Model (CIM) add-on helps you normalize your data from different sources and make it easier to analyze and report on it3. One of the functionalities that the CIM add-on relies on to normalize fields with different names is field aliases3. Field aliases allow you to assign an alternative name to an existing field without changing the original field name or value2. By using field aliases, you can map different field names from different sources or sourcetypes to a common field name that conforms to the CIM standard3. Therefore, option B is correct, while options A, C and D are incorrect.
29.When should you use the transaction command instead of the scats command?
A. When you need to group on multiple values.
B. When duration is irrelevant in search results. .
C. When you have over 1000 events in a transaction.
D. When you need to group based on start and end constraints.
Answer: D
Explanation:
The transaction command is used to group events into transactions based on some common characteristics, such as fields, time, or both. The transaction command can also specify start and end constraints for the transactions, such as a field value that indicates the beginning or the end of a transaction. The stats command is used to calculate summary statistics on the events, such as count, sum, average, etc. The stats command cannot group events based on start and end constraints, but only on fields or time buckets. Therefore, the transaction command should be used instead of the stats command when you need to group events based on start and end constraints.
30.Which of the following statements describes field aliases?
A. Field alias names replace the original field name.
B. Field aliases can be used in lookup file definitions.
C. Field aliases only normalize data across sources and sourcetypes.
D. Field alias names are not case sensitive when used as part of a search.
Answer: B
Explanation:
Field aliases are alternative names for fields in Splunk. Field aliases can be used to normalize data across different sources and sourcetypes that have different field names for the same concept. For example, you can create a field alias for src_ip that maps to clientip, source_address, or any other field name that represents the source IP address in different sourcetypes. Field aliases can also be used in lookup file definitions to map fields in your data to fields in the lookup file. For example, you can use a field alias for src_ip to map it to ip_address in a lookup file that contains geolocation information for IP addresses. Field alias names do not replace the original field name, but rather create a copy of the field with a different name. Field alias names are case sensitive when used as part of a search, meaning that src_ip and SRC_IP are different fields.
Get Full SPLK-1002 Practice Exam Questions
Preparing with real exam-like questions is the best way to boost your confidence and ensure success in the SPLK-1002 Splunk Core Certified Power User exam. Access the complete practice exam and study guide by clicking the link below:
LEAVE A COMMENT